
Reactor는 Pivotal의 오픈소스 프로젝트로, JVM 위에서 동작하는 논블럭킹 애플리케이션을 만들기 위한 리액티브 라이브러리입니다. Reactor는 RxJava 2와 함께 Reactive Stream의 구현체이기도 하고, Spring Framework 5부터 리액티브 프로그래밍을 위해 지원되는 라이브러리입니다. RxJava에 익숙한 필자가 Reactor를 사용하면서 느낀 것은 RxJava와 많은 공통점이 있으며 큰 차이점이 있다면 Reactor는 최소 Java8에서 동작하며 Java8의 피쳐를 잘 지원한다는 점입니다.
본문에서는 필자가 스프링 프레임워크 WebFlux환경에서 개발을 할 때 Reactor에 대해서 알게 된 점을 공유하고자 합니다. 쉬운 이해를 위해 간단한 자바 애플리케이션 예제 코드를 통해 소개하도록 하겠습니다. 본 예제에서 사용된 자바 버전은 Java8이며, Reactor 버전은 3.1.7 임을 알려드립니다.
Mono와 Flux
우선 예제에 들어가기 앞서 Mono와 Flux의 차이점을 알 필요가 있습니다. Mono는 0-1개의 결과만을 처리하기 위한 Reactor의 객체이고, Flux는 0-N개인 여러 개의 결과를 처리하는 객체입니다. Reactor를 사용해 일련의 스트림을 코드로 작성하다 보면 보통 여러 스트림을 하나의 결과를 모아줄 때 Mono를 쓰고, 각각의 Mono를 합쳐서 여러 개의 값을 여러 개의 값을 처리하는 Flux로 표현할 수도 있습니다. 자세한 설명은 Reactor의 Mono reference와 Flux reference를 읽어 보시면 됩니다.
Mono와 Flux모두 Reactive Stream의 Publisher 인터페이스를 구현하고 있으며, Reactor에서 제공하는 풍부한 연산자들(operators)의 조합을 통해 스트림을 표현할 수 있습니다. 예를 들어 Flux에서 하나의 결과로 값을 모아주는 reduce연산자는 Mono를 리턴하고, Mono에서 flatMapMany라는 연산자를 사용하면 하나의 값으로부터 여러 개의 값을 취급하는 Flux를 리턴할 수 있습니다. 그리고 Publisher인터페이스에 정의된 subscribe메서드를 호출함으로써 Mono나 Flux가 동작하도록 할 수 있습니다. 자세한 내용은 예제 코드를 통해 다루도록 하겠습니다.
하나의 스트림에서 여러 스트림으로
여기서는 하나의 스트림에서 여러 개의 스트림으로 갈라질 때 Flux와 Mono를 어떻게 적절히 섞어서 사용했는지 예제를 통해 보도록 하겠습니다.
과일바구니 예제
여기서 사용할 예제는 과일바구니 예제입니다. basket1부터 basket3까지 3개의 과일바구니가 있으며, 과일바구니 안에는 과일을 중복해서 넣을 수 있습니다. 그리고 이 바구니를 List로 가지는 baskets가 있습니다. Flux.fromIterable에 Iterable type의 인자를 넘기면 이 Iterable을 Flux로 변환해줍니다. 이러한 예제를 만든 이유는 스프링에서 WebClient를 이용하여 특정 HTTP API를 호출하고 받은 JSON 응답에 여러 배열이 중첩되어 있고, 여기서 또 다른 API를 호출하거나 데이터를 조작하는 경우가 있었습니다.
처음엔 API 호출을 몇 번하고 원하는 데이터로 조작하고자 하는 필요에서 시작하였지만, 받은 데이터를 막상 적절한 연산자의 조합으로 하려고 접근하다 보면 어려워지고, 어떻게 하면 쉽게 풀 수 있을까 생각해보았습니다. 그리고 간단한 예제를 만들어 연습해보는 것이 좋겠다는 생각이 들었습니다. 따라서 이러한 연습을 위해 여기서는 과일바구니를 표현하는 리스트를 만들어 시작을 해보도록 하겠습니다.
public static void main(String [] args) {
final List<String> basket1 = Arrays.asList(new String[]{"kiwi", "orange", "lemon", "orange", "lemon", "kiwi"});
final List<String> basket2 = Arrays.asList(new String[]{"banana", "lemon", "lemon", "kiwi"});
final List<String> basket3 = Arrays.asList(new String[]{"strawberry", "orange", "lemon", "grape", "strawberry"});
final List<List<String>> baskets = Arrays.asList(basket1, basket2, basket3);
final Flux<List<String>> basketFlux = Flux.fromIterable(baskets);
}
바구니 속 과일 종류(중복 없이) 및 각 종류별 개수 나누기
basketFlux로부터 중복 없이 각 과일 종류를 나열하고, 각 과일이 몇 개씩 들어있는지 각 바구니마다 출력하는 코드를 작성해보도록 하겠습니다. 단순히 Reactor사용 없이 Java에 있는 방법만으로 함수형 프로그래밍도 아닌 절차 지향적으로 생각해보면 어렵지 않습니다. baskets를 for each loop로 돌면서 Set에 담을 수도 있고, 각 과일의 개수는 Set에 처음으로 들어가는 경우 Map에 key값으로 1 값을 갖게 만들고, 그 외의 경우는 1씩 증가시키는 방법으로 과일의 개수를 셀 수 있습니다.
그렇다면 basketFlux에서 연산자들의 조합으로 어떻게 이 2가지 과제를 할 수 있을까요? 우선 이 기능을 추상화한 연산자를 찾아볼 수 있습니다. 중복 없이 값을 처리하는 연산자로 distinct가 있고, 각 key별로 스트림을 관리하기 원한다면 key를 기준으로 Flux로 그룹을 묶을 수 있는 groupBy가 있습니다. 그리고 스트림에서 내려주는 값의 개수를 셀 수 있는 count라는 연산자도 있습니다. 그런데 이것들을 하려면 basketFlux로부터 각각의 바구니들을 꺼내야 합니다. 이렇게 값을 꺼내서 새로운 Publisher로 바꿔줄 수 있는 연산자로는 대표적으로 flatMap, flatMapSequential, concatMap이 있습니다. flatMap은 리턴하는 Publisher가 비동기로 동작할 때 순서를 보장하지 않으므로, 순서 보장을 하려면 flatMapSequential 또는 concatMap을 사용해야 하는데, 여기서는 concatMap을 사용하도록 하겠습니다. flatMapSequential과 concatMap의 차이는 concatMap은 인자로 지정된 함수에서 리턴하는 Publisher의 스트림이 다 끝난 후에 그다음 넘어오는 값의 Publisher스트림을 처리하지만, flatMapSequential은 일단 오는 대로 구독하고 결과는 순서에 맞게 리턴하는 역할을 해서, 비동기 환경에서 동시성을 지원하면서도 순서를 보장할 때 쓰이는 것이 차이점입니다.
basketFlux.concatMap(basket -> {
final Mono<List<String>> distinctFruits = Flux.fromIterable(basket).distinct().collectList();
final Mono<Map<String, Long>> countFruitsMono = Flux.fromIterable(basket)
.groupBy(fruit -> fruit) // 바구니로 부터 넘어온 과일 기준으로 group을 묶는다.
.concatMap(groupedFlux -> groupedFlux.count()
.map(count -> {
final Map<String, Long> fruitCount = new LinkedHashMap<>();
fruitCount.put(groupedFlux.key(), count);
return fruitCount;
}) // 각 과일별로 개수를 Map으로 리턴
) // concatMap으로 순서보장
.reduce((accumulatedMap, currentMap) -> new LinkedHashMap<String, Long>() { {
putAll(accumulatedMap);
putAll(currentMap);
}}); // 그동안 누적된 accumulatedMap에 현재 넘어오는 currentMap을 합쳐서 새로운 Map을 만든다. // map끼리 putAll하여 하나의 Map으로 만든다.
// return ???
});
distinctFruits와 countFruitsMono라는 이름으로 앞서 소개한 연산자들로 조합을 했습니다.
과일의 중복이 없도록 모으는 distinctFruits에서는 List로 변환하기 위해 Flux에서 제공하는 collectList를 이용했습니다. 이렇게 하면 Flux에서 넘어오는 각각의 항목들을 하나의 리스트로 모아주는 Mono로 변환할 수 있습니다. countFruitsMono에서는 각 과일의 개수를 key, value를 갖는 Map (자료구조 interface Map)으로 모으기 위해서 reduce를 이용해서 합쳤습니다. 순서를 보장하기 위해 concatMap과 LinkedHashMap을 사용했습니다. 이렇게 하면 순서대로 넘어온 각 과일의 개수를 순서대로 Map에 순서에 따라 모을 수 있습니다.
이렇게 만들어 놓으니 이제 이 둘을 각각 합쳐서 하나의 스트림으로 리턴을 해줘야 합니다. 리턴 부분은 아직 물음표로 주석처리를 해두었습니다. 이렇게 2개의 스트림을 하나의 객체를 리턴하는 Publisher로 합쳐주는 연산자로는 Flux.zip이 있습니다. 이것을 합쳐줄 객체를 만들기 위해 FruitInfo라는 클래스를 정의하고 zip연산자를 사용해보도록 하겠습니다.
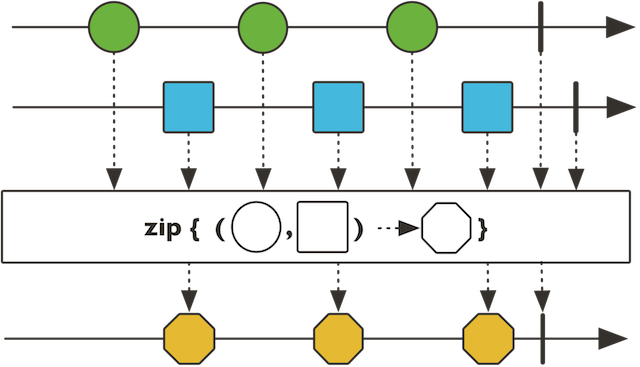
FruitInfo 클래스
public class FruitInfo {
private final List<String> distinctFruits;
private final Map<String, Long> countFruits;
public FruitInfo(List<String> distinctFruits, Map<String, Long> countFruits) {
this.distinctFruits = distinctFruits;
this.countFruits = countFruits;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
FruitInfo fruitInfo = (FruitInfo) o;
if (distinctFruits != null ? !distinctFruits.equals(fruitInfo.distinctFruits) : fruitInfo.distinctFruits != null)
return false;
return countFruits != null ? countFruits.equals(fruitInfo.countFruits) : fruitInfo.countFruits == null;
}
@Override
public int hashCode() {
int result = distinctFruits != null ? distinctFruits.hashCode() : 0;
result = 31 * result + (countFruits != null ? countFruits.hashCode() : 0);
return result;
}
@Override
public String toString() {
return "FruitInfo{" +
"distinctFruits=" + distinctFruits +
", countFruits=" + countFruits +
'}';
}
}
zip연산자로 합친 예제
basketFlux.concatMap(basket -> {
final Mono<List<String>> distinctFruits = Flux.fromIterable(basket).distinct().collectList();
final Mono<Map<String, Long>> countFruitsMono = Flux.fromIterable(basket)
.groupBy(fruit -> fruit) // 바구니로 부터 넘어온 과일 기준으로 group을 묶는다.
.concatMap(groupedFlux -> groupedFlux.count()
.map(count -> {
final Map<String, Long> fruitCount = new LinkedHashMap<>();
fruitCount.put(groupedFlux.key(), count);
return fruitCount;
}) // 각 과일별로 개수를 Map으로 리턴
) // concatMap으로 순서보장
.reduce((accumulatedMap, currentMap) -> new LinkedHashMap<String, Long>() { {
putAll(accumulatedMap);
putAll(currentMap);
}}) // 그동안 누적된 accumulatedMap에 현재 넘어오는 currentMap을 합쳐서 새로운 Map을 만든다. // map끼리 putAll하여 하나의 Map으로 만든다.
return Flux.zip(distinctFruits, countFruitsMono, (distinct, count) -> new FruitInfo(distinct, count));
}).subscribe(System.out::println);
결과
FruitInfo{distinctFruits=[kiwi, orange, lemon], countFruits={kiwi=2, orange=2, lemon=2}}
FruitInfo{distinctFruits=[banana, lemon, kiwi], countFruits={banana=1, lemon=2, kiwi=1}}
FruitInfo{distinctFruits=[strawberry, orange, lemon, grape], countFruits={strawberry=2, orange=1, lemon=1, grape=1}}
distinct 된 리스트와 각 과일의 개수를 묶은 리스트를 하나의 리스트로 묶어서 각각 출력하는 것을 확인할 수 있습니다. 그런데 이런 식의 방식은 너무 비효율적입니다. distinctFruits와 countFruitsMono모두 Flux.fromIterable(basket)로부터 시작해서 각각 basket을 독립적으로 순회합니다. 절차 지향으로 생각하면 하나의 for each loop 안에서 2가지를 한 번에 해결할 수 있는데 여기서는 총 2번 basket을 순회하고, 특별히 스레드를 지정하지 않았기 때문에 동기, 블록킹 방식으로 동작합니다. 논 블록킹 라이브러리의 장점을 전혀 살릴 수 없고, 효율성도 떨어집니다. 단순히 Reactor에서 제공하는 연산자들의 조합의 코드일 뿐입니다.
그래서 비동기 논 블록킹으로 동시성도 살리면서, 순차적으로 basket을 두 번 순회하지 않는 방법을 다음 코드에서 다뤄보고자 합니다.
병렬로 두 스트림 합쳐보기
Reactor나 RxJava 모두 동시성 지원을 위해 Scheduler를 제공합니다. 적절한 Scheduler를 적절한 위치에 지정함으로써 동시성과 실행 순서를 적절히 관리할 수 있습니다. 기본적으로 스케줄러를 지정하지 않고 사용하는 연산자가 특정한 스케줄러에서 동작하지 않는다면, Reactor의 Flux나 Mono는 구독할 때 현재 스레드에서 동작합니다. 따라서 위의 코드도 로그를 찍어봄으로써 스레드를 확인해보면 모든 코드가 main thread에서 동기로 실행되는 것을 확인할 수 있습니다. 스프링 프레임워크 5부터 제공하는 WebClient를 사용하면 다른 스레드로 이미 바뀌어서 비동기로 동작하겠지만, 해당 스레드 안에서도 몇몇 스트림은 병렬로 실행시키고자 할 필요가 있을 수 있습니다. 그렇다면 어떻게 스케줄러를 지정하여 1) 과일의 종류를 뽑아내는 것과 2) 과일의 개수를 뽑아내는 이 2가지 작업을 병렬로 실행할 수 있을지 알아보도록 하겠습니다.
병렬 스케줄러 (Schedulers.parallel())
Reactor의 스케줄러 관련 문서를 보면 기본적으로 제공하는 몇 가지 스케줄러에 대한 설명이 있습니다. 여기서는 병렬로 여러 개를 실행시키기 위해 Schedulers.parallel()을 사용하도록 했는데, 이 스케줄러는 병렬 실행을 위해 CPU 코어 개수만큼 워커를 만들어 병렬로 실행을 지원하는 스케줄러 입니다. RxJava에서는 Schedulers.computation()이 해당 스케줄러에 해당되는 것으로 알고 있습니다. 필자의 머신에서는 쿼드코어에 하이퍼스레딩의 영향으로 최대 8개의 스레드로 해당 스케줄러가 동작하는 것을 확인할 수 있었습니다.
subscribeOn으로 스케줄러 전환하기
subscribeOn연산자는 해당 스트림을 구독할 때 동작하는 스케줄러를 지정할 수 있습니다. 여기서 distinctFruits와countFruitsMono가 각각 병렬로 동작하길 원하므로 subscribeOn(Schedulers.parallel())을 각각 추가하여 실행시켜 보았습니다. 그런데 이 자바 애플리케이션은 아무 결과도 확인 못하고 끝나 버립니다.
basketFlux.concatMap(basket -> {
final Mono<List<String>> distinctFruits = Flux.fromIterable(basket).distinct().collectList().subscribeOn(Schedulers.parallel());
final Mono<Map<String, Long>> countFruitsMono = Flux.fromIterable(basket)
.groupBy(fruit -> fruit) // 바구니로 부터 넘어온 과일 기준으로 group을 묶는다.
.concatMap(groupedFlux -> groupedFlux.count()
.map(count -> {
final Map<String, Long> fruitCount = new LinkedHashMap<>();
fruitCount.put(groupedFlux.key(), count);
return fruitCount;
}) // 각 과일별로 개수를 Map으로 리턴
) // concatMap으로 순서보장
.reduce((accumulatedMap, currentMap) -> new LinkedHashMap<String, Long>() { {
putAll(accumulatedMap);
putAll(currentMap);
}}) // 그동안 누적된 accumulatedMap에 현재 넘어오는 currentMap을 합쳐서 새로운 Map을 만든다. // map끼리 putAll하여 하나의 Map으로 만든다.
.subscribeOn(Schedulers.parallel());
return Flux.zip(distinctFruits, countFruitsMono, (distinct, count) -> new FruitInfo(distinct, count));
}).subscribe(System.out::println);
왜냐하면 parallel스케줄러는 데몬스레드(Deamon Thread)인데 이 애플리케이션이 처음 동작하는 main thread는 데몬스레드가 아닌 비-데몬스레드(Non-Deamon Thread)이기 때문에 main메서드가 끝나버리며 아무런 비-데몬스레드가 남지 않아 종료되기 때문입니다. 종료되지 않고 계속 동작해야 하는 서버 환경의 애플리케이션에서는 괜찮겠지만, 본 애플리케이션은 main메서드가 끝난 후 비-데몬스레드가 하나도 남아있지 않아 종료됩니다. 이를 방지하기 위해 CountDownLatch를 이용하여 await()으로 애플리케이션이 종료되지 않게 main스레드가 동작이 끝날 때까지 기다리도록 하겠습니다. 위의 스트림이 정상적으로 또는 에러가 나서 종료한 경우에 countDown메서드를 호출하여 더 이상 기다리지 않고 종료되도록 하겠습니다. 혹시 모르게 오랫동안 기다리는 경우를 막기 위해 await(2, TimeUnit.SECONDS)으로 2초 정도의 timeout을 두도록 했습니다.
basketFlux.concatMap(basket -> {
// ... 생략
return Flux.zip(distinctFruits, countFruitsMono, (distinct, count) -> new FruitInfo(distinct, count));
}).subscribe(
System.out::println, // 값이 넘어올 때 호출 됨, onNext(T)
error -> {
System.err.println(error);
countDownLatch.countDown();
}, // 에러 발생시 출력하고 countDown, onError(Throwable)
() -> {
System.out.println("complete");
countDownLatch.countDown();
} // 정상적 종료시 countDown, onComplete()
);
countDownLatch.await(2, TimeUnit.SECONDS);
결과
FruitInfo{distinctFruits=[kiwi, orange, lemon], countFruits={kiwi=2, orange=2, lemon=2}}
FruitInfo{distinctFruits=[banana, lemon, kiwi], countFruits={banana=1, lemon=2, kiwi=1}}
FruitInfo{distinctFruits=[strawberry, orange, lemon, grape], countFruits={strawberry=2, orange=1, lemon=1, grape=1}}
complete
결과가 잘 나오는 것을 확인할 수 있습니다. 병렬로 실행되는지 확인하기 위해 distinctFruits와 countFruitsMono의 각각의 시작점 Flux.fromIterable(basket)에 log()라는 메서드를 추가하도록 하겠습니다. 그러면 log()를 호출한 지점 위에서 넘어오는 값을 로그로 확인하며 디버깅하기 좋습니다. Reactor에서 유용한 메서드 중 하나입니다.
basketFlux.concatMap(basket -> {
final Mono<List<String>> distinctFruits = Flux.fromIterable(basket).log().distinct().collectList().subscribeOn(Schedulers.parallel());
final Mono<Map<String, Long>> countFruitsMono = Flux.fromIterable(basket).log()
.groupBy(fruit -> fruit) // 바구니로 부터 넘어온 과일 기준으로 group을 묶는다.
.concatMap(groupedFlux -> groupedFlux.count()
.map(count -> {
final Map<String, Long> fruitCount = new LinkedHashMap<>();
fruitCount.put(groupedFlux.key(), count);
return fruitCount;
}) // 각 과일별로 개수를 Map으로 리턴
) // concatMap으로 순서보장
.reduce((accumulatedMap, currentMap) -> new LinkedHashMap<String, Long>() { {
putAll(accumulatedMap);
putAll(currentMap);
}}) // 그동안 누적된 accumulatedMap에 현재 넘어오는 currentMap을 합쳐서 새로운 Map을 만든다. // map끼리 putAll하여 하나의 Map으로 만든다.
.subscribeOn(Schedulers.parallel());
return Flux.zip(distinctFruits, countFruitsMono, (distinct, count) -> new FruitInfo(distinct, count));
}).subscribe(
System.out::println, // 값이 넘어올 때 호출 됨, onNext(T)
error -> {
System.err.println(error);
countDownLatch.countDown();
}, // 에러 발생시 출력하고 countDown, onError(Throwable)
() -> {
System.out.println("complete");
countDownLatch.countDown();
} // 정상적 종료시 countDown, onComplete()
);
[ INFO] (parallel-1) | onSubscribe([Synchronous Fuseable] FluxIterable.IterableSubscriptionConditional)
[ INFO] (parallel-2) | onSubscribe([Synchronous Fuseable] FluxIterable.IterableSubscription)
[ INFO] (parallel-1) | request(unbounded)
[ INFO] (parallel-2) | request(256)
[ INFO] (parallel-1) | onNext(kiwi)
[ INFO] (parallel-2) | onNext(kiwi)
[ INFO] (parallel-1) | onNext(orange)
[ INFO] (parallel-1) | onNext(lemon)
[ INFO] (parallel-1) | onNext(orange)
[ INFO] (parallel-1) | onNext(lemon)
[ INFO] (parallel-1) | onNext(kiwi)
[ INFO] (parallel-1) | onComplete()
[ INFO] (parallel-2) | request(1)
[ INFO] (parallel-2) | onNext(orange)
[ INFO] (parallel-2) | onNext(lemon)
[ INFO] (parallel-2) | onNext(orange)
[ INFO] (parallel-2) | onNext(lemon)
[ INFO] (parallel-2) | onNext(kiwi)
[ INFO] (parallel-2) | request(1)
[ INFO] (parallel-2) | onComplete()
[ INFO] (parallel-2) | request(2)
FruitInfo{distinctFruits=[kiwi, orange, lemon], countFruits={kiwi=2, orange=2, lemon=2}}
[ INFO] (parallel-2) | cancel()
[ INFO] (parallel-2) | cancel()
[ INFO] (parallel-3) | onSubscribe([Synchronous Fuseable] FluxIterable.IterableSubscriptionConditional)
[ INFO] (parallel-4) | onSubscribe([Synchronous Fuseable] FluxIterable.IterableSubscription)
[ INFO] (parallel-3) | request(unbounded)
[ INFO] (parallel-4) | request(256)
[ INFO] (parallel-3) | onNext(banana)
[ INFO] (parallel-4) | onNext(banana)
[ INFO] (parallel-3) | onNext(lemon)
[ INFO] (parallel-4) | request(1)
[ INFO] (parallel-3) | onNext(lemon)
[ INFO] (parallel-4) | onNext(lemon)
[ INFO] (parallel-3) | onNext(kiwi)
[ INFO] (parallel-4) | onNext(lemon)
[ INFO] (parallel-3) | onComplete()
[ INFO] (parallel-4) | onNext(kiwi)
[ INFO] (parallel-4) | onComplete()
[ INFO] (parallel-4) | request(2)
[ INFO] (parallel-4) | request(1)
FruitInfo{distinctFruits=[banana, lemon, kiwi], countFruits={banana=1, lemon=2, kiwi=1}}
... 이하 생략 ...
처음엔 parallel-1과 parallel-2이 같이 동작하고, 그다음 순서로 parallel-3과 parallel-4이 같이 동작하는 것을 로그를 통해 확인할 수 있습니다.
basket당 하나의 스트림만 공유하며 과일종류와 개수 뽑아내기
지금까지 진행해온 과정에서 아쉬운 점을 좀 더 개선해보고자 합니다. distinctFruits와 countFruitsMono 모두 Flux.fromIterable(basket)에서 출발하기 때문에 병렬로 동작해도 baskets를 각각 순회하여 중복되는 동작이라는 점은 처음의 예제와 다를 게 없습니다. 또한 몇 개 안 되는 데이터를 각각 병렬로 처리하는 것은 스레드를 생성하고 컨텍스트 스위칭을 하는 비용을 생각하면 배보다 배꼽이 클 수도 있습니다. baskets을 순회하는 공통 작업을 하나의 스트림에서 하는 방법은 없을까요? 먼저 관련된 배경지식을 다루고 그 방법을 함께 살펴보도록 하겠습니다.
Hot, Cold 개념
Hot과 Cold 개념은 RxJava에도 있는 개념으로 Reactor의 Hot, Cold 개념은 공식문서 Hot vs Cold를 통해서 확인하실 수 있습니다.
간단히 설명하면 Cold는 각 Flux나 Mono를 subscribe 할 때마다 매번 독립적으로 새로 데이터를 생성해서 동작합니다. 즉, subscribe호출 전까지 아무런 동작도 하지 않고, subscribe를 호출하면 새로운 데이터를 생성합니다. 기본적으로 특별하게 Hot을 취급하는 연산자가 아닌 이상 Flux나 Mono는 Cold로 동작합니다. 따라서 지금까지 예제는 basket으로부터 값을 꺼내어 각각 따로 새로운 데이터를 생성하기 때문에 각각 중복된 작업을 새로 시작하게 동작합니다.
그러나 Hot은 구독하기 전부터 데이터의 스트림이 동작할 수 있습니다. 예를 들어서 마우스 클릭이나 키보드 입력 같은 이벤트 성은 구독여부와 상관없이 발생하고 있다가 이 이벤트를 구독하는 여러 구독자가 붙으면 해당 이벤트가 발생할 때 모두 동일한 값을 전달받을 수 있습니다. 즉, Hot에 해당하는 스트림을 여러 곳에서 구독을 하면 현재 스트림에서 나오는 값을 구독하는 구독자들은 동일하게 받을 수 있습니다.
여기서 주목할 점은 Cold를 Hot으로 바꿀 수 있는 연산자가 있다는 것입니다. 처음 Hot에 대해서 예제를 든 마우스클릭이나 키보드입력같은 이벤트를 떠올리면 쉽게 상상이 안되는데요. Cold는 구독을 하면 값을 생성하기 시작합니다. 그러나 Cold를 Hot으로 바꾸면 구독여부와 상관없이 값을 생성 안 하다가 특정 시점에 값을 생성하도록 제어하여 구독하는 구독자(Subscriber)들이 동일한 값을 받을 수 있도록 할 수 있습니다. 이에 대해 알아보겠습니다.
Connectable Flux
Connectable Flux는 Cold에서 Hot으로 바꾸기 위해서는 Connectable Flux로 변환하는 과정이 필요합니다. 공식문서에 설명되어 있듯 기본적으로 publish라는 연산자를 호출하면 바꿀 수 있습니다. 이렇게 변환된 Flux에서 connect()라는 메서드를 호출할 수 있는데, 이 메서드가 여러 구독자들이 Connectable Flux를 구독한 후 값을 생성하여 각 구독자에게 보내기 시작하게 하는 메서드입니다. 즉, 우리의 예제에서는 distinctFruits와 countFruitsMono가 구독을 모두 완료한 후에 connect()를 호출할 수 있게 해주면 됩니다. 어떻게 할 수 있을까요? 다행히 Reactor에서는 autoConnect나 refCount에 인자 값으로 최소 구독하는 구독자의 개수를 지정해서 이 개수가 충족되면 자동으로 값을 생성할 수 있게 연산자를 제공합니다. 2개의 차이점이 있다면 autoConnect는 이름 그대로 최소 구독 개수를 만족하면 자동으로 connect()를 호출하는 역할만 하고, refCount는 autoConnect가 하는 일에 더해서 구독하고 있는 구독자의 개수를 세다가 하나도 구독하는 곳이 없으면 기존 소스의 스트림도 구독을 해제하는 역할을 합니다. interval처럼 무한히 일정 간격으로 값이 나오는 스트림을 Hot으로 바꾼다면 refCount를 고려해 볼 수 있을 것입니다. 호출되는 소스가 무한으로 값을 생성한다면 더 이상 구독을 안 할 때 해제하게 refCount를 고려해볼 수 있지만, 우리는 제한된 개수의 데이터만 다 다루면 알아서 완료가 되기 때문에 autoConnect로 충분하다고 생각합니다. 참고로 여기서 소개한 2개의 연산자는 인자 값을 없을 경우 최초 구독이 발생할 때 connect()를 호출하도록 동작하고, publish().refCount()를 하나의 연산자로 추상화한 연산자를 share()라고 합니다. 그 밖에 RxJava의 ConnectableFlowable도 동일한 기능을 제공하는 것을 문서를 통해 확인할 수 있었습니다.
2개 구독자가 구독하면 자동으로 동작하게 Hot Flux 만들기
이제 코드로 공통적으로 사용하는 Flux.fromIterable(basket)을 Hot으로 만들어보도록 하겠습니다.
설명에서 소개한 바와 같이 publish().autoConnect(2)를 사용하도록 하겠습니다. 이렇게 하면 Hot으로 변환된 ConnectableFlux를 최소 2개의 구독자가 구독을 하면 자동으로 구독하는 Flux를 리턴합니다. 이를 소스코드에서는 source라는 변수에 지정하고, distinctFruits와 countFruitsMono모두 source를 공통으로 쓰도록 했습니다. Flux.fromIterable(basket) 뒤에 log()는 그대로 두었습니다.
한 번만 값이 나오나 확인하기 위함입니다. 추가로 distinctFruits와 countFruitsMono에서 subscribeOn은 제거했습니다. 굳이 몇 개 안 되는 데이터를 병렬로 돌릴 필요가 없어 보였고, 하나의 스레드에서 Flux.fromIterable(basket)가 한 번만 동작하면서 2가지 스트림으로 동작할 수 있음을 보여주기 위함입니다.
basketFlux.concatMap(basket -> {
final Flux<String> source = Flux.fromIterable(basket).log().publish().autoConnect(2);
final Mono<List<String>> distinctFruits = source.distinct().collectList();
final Mono<Map<String, Long>> countFruitsMono = source
.groupBy(fruit -> fruit) // 바구니로 부터 넘어온 과일 기준으로 group을 묶는다.
.concatMap(groupedFlux -> groupedFlux.count()
.map(count -> {
final Map<String, Long> fruitCount = new LinkedHashMap<>();
fruitCount.put(groupedFlux.key(), count);
return fruitCount;
}) // 각 과일별로 개수를 Map으로 리턴
) // concatMap으로 순서보장
.reduce((accumulatedMap, currentMap) -> new LinkedHashMap<String, Long>() { {
putAll(accumulatedMap);
putAll(currentMap);
}}); // 그동안 누적된 accumulatedMap에 현재 넘어오는 currentMap을 합쳐서 새로운 Map을 만든다. // map끼리 putAll하여 하나의 Map으로 만든다.
return Flux.zip(distinctFruits, countFruitsMono, (distinct, count) -> new FruitInfo(distinct, count));
}).subscribe(
System.out::println, // 값이 넘어올 때 호출 됨, onNext(T)
error -> {
System.err.println(error);
countDownLatch.countDown();
}, // 에러 발생시 출력하고 countDown, onError(Throwable)
() -> {
System.out.println("complete");
countDownLatch.countDown();
} // 정상적 종료시 countDown, onComplete()
);
결과
[ INFO] (main) | onSubscribe([Synchronous Fuseable] FluxIterable.IterableSubscription)
[ INFO] (main) | onNext(kiwi)
[ INFO] (main) | onNext(orange)
[ INFO] (main) | onNext(lemon)
[ INFO] (main) | onNext(orange)
[ INFO] (main) | onNext(lemon)
[ INFO] (main) | onNext(kiwi)
[ INFO] (main) | onComplete()
FruitInfo{distinctFruits=[kiwi, orange, lemon], countFruits={kiwi=2, orange=2, lemon=2}}
...이하생략
이하 결과를 생략했지만 모두 main스레드에서 값이 잘 나오는 것을 확인할 수 있습니다. 여기서는 동일한 스레드이기 때문에 countDownLatch도 필요가 없습니다. 두 군데서 구독할 때만 값이 나오는지 확인하기 위해 zip에서 쓰이는 distinctFruits의 source를 Flux.fromIterable(basket)로 바꿔서 source가 한 번만 구독되도록 해보겠습니다.
source를 한 곳 countFruitsMono에서만 구독할 때 예제
basketFlux.concatMap(basket -> {
final Flux<String> source = Flux.fromIterable(basket).log().publish().autoConnect(2);
final Mono<List<String>> distinctFruits = Flux.fromIterable(basket).distinct().collectList();
final Mono<Map<String, Long>> countFruitsMono = source.
//생략...
return Flux.zip(distinctFruits, countFruitsMono, (distinct, count) -> new FruitInfo(distinct, count));
}).subscribe(/* 생략.. */);
구독한 후 아무 값도 나오지 않습니다. complete도 불리지 않는 것을 확인할 수 있습니다.
Hot 이후에 각 스트림만 비동기로 처리하기
위의 예제에서는 몇 개 안 되는 데이터라 같은 스레드에서 동기로 실행시켰지만, 데이터가 많아지거나 현재 스레드가 다른 일을 하게 하기 위해서 distinct나 groupBy count 등의 연산을 하는 지점은 각각 비동기로 처리하고자 하는 필요가 생길 수도 있습니다. 그러나 앞서 소개한 subscribeOn은 이런 경우 적절하지 않습니다. subscribeOn을 호출한 객체를 구독할 때는 해당 스트림 전체가 해당 스케줄러로 다 바뀌기 때문에, Hot인 source도 2개의 구독자가 구독을 하면 subscribeOn이 지정한 스레드에서 실행되게 되며, 그러면 distinct와 count로 갈라져 나오는 부분도 같은 스레드에서 실행되기 때문입니다. 이를 확인하기 위해 기존의 예제에서 distinctFruits와 countFruitsMono에 각각 subscribeOn(Schedulers.parallel())을 붙여서 실행해보겠습니다. 이때 각각 어느 스레드에서 동작하는지 확인하기 위해 log()를 붙였습니다.
basketFlux.concatMap(basket -> {
final Flux<String> source = Flux.fromIterable(basket).log().publish().autoConnect(2);
final Mono<List<String>> distinctFruits = source.distinct().collectList().log().subscribeOn(Schedulers.parallel());
final Mono<Map<String, Long>> countFruitsMono = source
.groupBy(fruit -> fruit) // 바구니로 부터 넘어온 과일 기준으로 group을 묶는다.
.concatMap(groupedFlux -> groupedFlux.count()
.map(count -> {
final Map<String, Long> fruitCount = new LinkedHashMap<>();
fruitCount.put(groupedFlux.key(), count);
return fruitCount;
}) // 각 과일별로 개수를 Map으로 리턴
) // concatMap으로 순서보장
.reduce((accumulatedMap, currentMap) -> new LinkedHashMap<String, Long>() { {
putAll(accumulatedMap);
putAll(currentMap);
}}) // 그동안 누적된 accumulatedMap에 현재 넘어오는 currentMap을 합쳐서 새로운 Map을 만든다. // map끼리 putAll하여 하나의 Map으로 만든다.
.log()
.subscribeOn(Schedulers.parallel());
return Flux.zip(distinctFruits, countFruitsMono, (distinct, count) -> new FruitInfo(distinct, count));
}).subscribe(/* 생략.. */);
결과
[ INFO] (parallel-1) | onSubscribe([Fuseable] MonoCollectList.MonoBufferAllSubscriber)
[ INFO] (parallel-2) | onSubscribe([Fuseable] MonoReduce.ReduceSubscriber)
[ INFO] (parallel-1) | request(32)
[ INFO] (parallel-2) | request(32)
[ INFO] (parallel-1) | onSubscribe([Synchronous Fuseable] FluxIterable.IterableSubscription)
[ INFO] (parallel-1) | onNext(kiwi)
[ INFO] (parallel-1) | onNext(orange)
[ INFO] (parallel-1) | onNext(lemon)
[ INFO] (parallel-1) | onNext(orange)
[ INFO] (parallel-1) | onNext(lemon)
[ INFO] (parallel-1) | onNext(kiwi)
[ INFO] (parallel-1) | onComplete()
[ INFO] (parallel-1) | onNext([kiwi, orange, lemon])
[ INFO] (parallel-1) | onComplete()
[ INFO] (parallel-1) | onNext({kiwi=2, orange=2, lemon=2})
FruitInfo{distinctFruits=[kiwi, orange, lemon], countFruits={kiwi=2, orange=2, lemon=2}}
처음엔 parallel-1과 parallel-2로 동작하는 듯했다가 결국 source는 parallel-1에서 실행됩니다. 2개의 구독자가 구독을 한 후 source가 parallel-1에서 시작되니 그 이후 동작도 다 parallel-1에서 실행되는 것입니다. subscribeOn으로 스케줄러를 지정하여 스위칭이 되면 이후 스트림은 계속 그 스케줄러에 의해 동작되기 때문입니다.
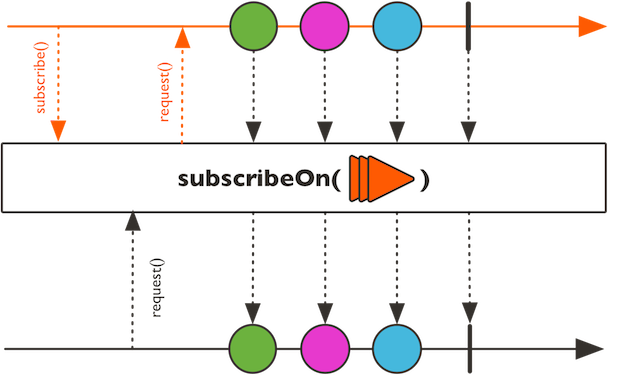
이때 필요한 것이 publishOn연산자입니다. 이 연산자가 호출된 위치 이후에 실행되는 연산자들은 publishOn에서 지정된 스케줄러에서 실행되도록 할 수 있습니다. subscribeOn과의 차이점은 마블 다이어그램을 통해 확인하실 수 있습니다. 그렇다면 publishOn을 각각 source 바로 뒤에 호출되도록 붙여 보겠습니다.
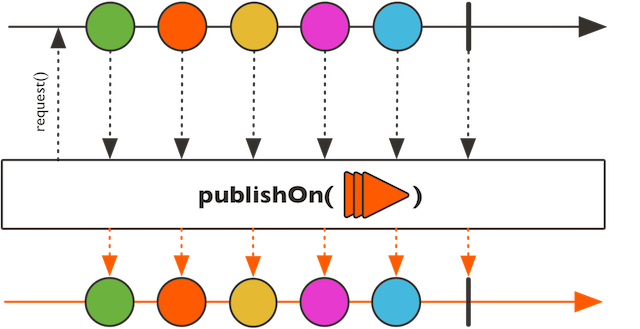
basketFlux.concatMap(basket -> {
final Flux<String> source = Flux.fromIterable(basket).log().publish().autoConnect(2);
final Mono<List<String>> distinctFruits = source.publishOn(Schedulers.parallel()).distinct().collectList().log();
final Mono<Map<String, Long>> countFruitsMono = source.publishOn(Schedulers.parallel())
.groupBy(fruit -> fruit) // 바구니로 부터 넘어온 과일 기준으로 group을 묶는다.
.concatMap(groupedFlux -> groupedFlux.count()
.map(count -> {
final Map<String, Long> fruitCount = new LinkedHashMap<>();
fruitCount.put(groupedFlux.key(), count);
return fruitCount;
}) // 각 과일별로 개수를 Map으로 리턴
) // concatMap으로 순서보장
.reduce((accumulatedMap, currentMap) -> new LinkedHashMap<String, Long>() { {
putAll(accumulatedMap);
putAll(currentMap);
}}) // 그동안 누적된 accumulatedMap에 현재 넘어오는 currentMap을 합쳐서 새로운 Map을 만든다. // map끼리 putAll하여 하나의 Map으로 만든다.
.log();
return Flux.zip(distinctFruits, countFruitsMono, (distinct, count) -> new FruitInfo(distinct, count));
}).subscribe(/* 생략.. */);
결과
...생략...
[ INFO] (main) | onNext(kiwi)
[ INFO] (main) | onNext(orange)
[ INFO] (main) | onNext(lemon)
[ INFO] (main) | onNext(orange)
[ INFO] (main) | onNext(lemon)
[ INFO] (main) | onNext(kiwi)
[ INFO] (main) | onComplete()
[ INFO] (parallel-1) | onNext([kiwi, orange, lemon])
[ INFO] (parallel-1) | onComplete()
[ INFO] (parallel-2) | onNext({kiwi=2, orange=2, lemon=2})
FruitInfo{distinctFruits=[kiwi, orange, lemon], countFruits={kiwi=2, orange=2, lemon=2}}
..중략..
[ INFO] (parallel-2) | onNext(banana)
[ INFO] (parallel-2) | onNext(lemon)
[ INFO] (parallel-2) | onNext(lemon)
[ INFO] (parallel-2) | onNext(kiwi)
[ INFO] (parallel-2) | onComplete()
[ INFO] (parallel-3) | onNext([banana, lemon, kiwi])
[ INFO] (parallel-3) | onComplete()
[ INFO] (parallel-4) | onNext({banana=1, lemon=2, kiwi=1})
FruitInfo{distinctFruits=[banana, lemon, kiwi], countFruits={banana=1, lemon=2, kiwi=1}}
...생략...
의도한 대로 각각 parallel-1과 parallel-2에서 실행되는 것을 확인할 수 있습니다. 그런데 처음에 source에서 시작할 때는 main스레드에서 시작하다가 publishOn으로 전체 스트림의 스케줄러가 바뀌면서 그다음 source는 parallel-2에서 실행되는 것을 확인할 수 있습니다. 만약 source가 하나의 지정한 스레드에서만 실행되도록 하고 싶다면 source에 subscribeOn을 추가할 수 있습니다. 이렇게 되면 source는 해당 스케줄러에 의해 동작하고 그 이후는 publishOn에 의해 바뀔 수 있습니다. 어떤 스케줄러를 지정할지는 필요에 따라 다를 듯 하지만, Reactor 공식문서 스케줄러를 읽어보고 저의 경우는 Schedulers.single()을 선택했습니다. 호출할 때마다 같은 스레드를 유지할 수 있기 때문에 매번 source를 구독할 때마다 같은 스레드에서 동작할 수 있기 때문입니다.
basketFlux.concatMap(basket -> {
final Flux<String> source = Flux.fromIterable(basket).log().publish().autoConnect(2).subscribeOn(Schedulers.single());
final Mono<List<String>> distinctFruits = source.publishOn(Schedulers.parallel()).distinct().collectList().log();
final Mono<Map<String, Long>> countFruitsMono = source.publishOn(Schedulers.parallel())
.groupBy(fruit -> fruit) // 바구니로 부터 넘어온 과일 기준으로 group을 묶는다.
.concatMap(groupedFlux -> groupedFlux.count()
.map(count -> {
final Map<String, Long> fruitCount = new LinkedHashMap<>();
fruitCount.put(groupedFlux.key(), count);
return fruitCount;
}) // 각 과일별로 개수를 Map으로 리턴
) // concatMap으로 순서보장
.reduce((accumulatedMap, currentMap) -> new LinkedHashMap<String, Long>() { {
putAll(accumulatedMap);
putAll(currentMap);
}}) // 그동안 누적된 accumulatedMap에 현재 넘어오는 currentMap을 합쳐서 새로운 Map을 만든다. // map끼리 putAll하여 하나의 Map으로 만든다.
.log();
return Flux.zip(distinctFruits, countFruitsMono, (distinct, count) -> new FruitInfo(distinct, count));
}).subscribe(/* 생략.. */);
결과 (설명상 필요한 부분만)
[ INFO] (single-1) | onNext(kiwi)
[ INFO] (single-1) | onNext(orange)
[ INFO] (single-1) | onNext(lemon)
[ INFO] (single-1) | onNext(orange)
[ INFO] (single-1) | onNext(lemon)
[ INFO] (single-1) | onNext(kiwi)
[ INFO] (single-1) | onComplete()
[ INFO] (parallel-1) | onNext([kiwi, orange, lemon])
[ INFO] (parallel-1) | onComplete()
[ INFO] (parallel-2) | onNext({kiwi=2, orange=2, lemon=2})
FruitInfo{distinctFruits=[kiwi, orange, lemon], countFruits={kiwi=2, orange=2, lemon=2}}
[ INFO] (single-1) | onNext(banana)
[ INFO] (single-1) | onNext(lemon)
[ INFO] (single-1) | onNext(lemon)
[ INFO] (single-1) | onNext(kiwi)
[ INFO] (single-1) | onComplete()
[ INFO] (parallel-3) | onNext([banana, lemon, kiwi])
[ INFO] (parallel-4) | onNext({banana=1, lemon=2, kiwi=1})
[ INFO] (parallel-3) | onComplete()
FruitInfo{distinctFruits=[banana, lemon, kiwi], countFruits={banana=1, lemon=2, kiwi=1}}
[ INFO] (single-1) | onSubscribe([Synchronous Fuseable] FluxIterable.IterableSubscription)
[ INFO] (single-1) | onNext(strawberry)
[ INFO] (single-1) | onNext(orange)
[ INFO] (single-1) | onNext(lemon)
[ INFO] (single-1) | onNext(grape)
[ INFO] (single-1) | onNext(strawberry)
[ INFO] (single-1) | onComplete()
[ INFO] (parallel-5) | onNext([strawberry, orange, lemon, grape])
[ INFO] (parallel-6) | onNext({strawberry=2, orange=1, lemon=1, grape=1})
[ INFO] (parallel-5) | onComplete()
결과는 필요한 부분만 뽑아 보았습니다. source는 single-1이라는 스레드에서 항상 동작하고, 그 이후에는 각각 parallel-1과parallel-2, parallel-3과parallel-4, parallel-5과parallel-6으로 동작하는 것을 확인할 수 있습니다.
디버깅과 테스팅
디버깅
Reactor나 RxJava와 같이 스트림을 여러 연산자의 조합으로 체이닝 동작하는 방식의 라이브러리는 디버깅이나 테스트가 쉽지 않은 점이 있습니다. 예를 들어 에러가 났을 때 어떤 연산자에서 오류가 났는지 알기 어려워서 중간에 doOnNext와 같은 연산자로 로그를 찍어야 할 수도 있습니다. 물론 Reactor에는 앞서 소개한 log()라는 연산자도 있어서 편리하게 로그를 찍어볼 수 있습니다. 그러나 이 log()도 직전의 값만 출력해주기 때문에 사이사이에 log()를 넣어주는 것도 번거로워 보였습니다. 그래서 Reactor의 디버깅 관련된 문서를 찾아보았습니다. Flux나 Mono를 구독하기 전 애플리케이션 시작 단계에서 Hooks.onOperatorDebug();를 호출하면 디버깅 모드를 활성화할 수 있으며, 이럴 경우 에러가 발생했을 때 출력되는 스택트레이스에 시작부터 에러가 났을 때까지 연산자의 목록을 모두 볼 수 있습니다. 공식문서에서는 다음과 같이 나온다고 소개되어 있는데, 해보니 실제로 에러가 났을 때 연산자들이 나오는 것을 확인할 수 있었습니다.
Error has been observed by the following operator(s):
|_ Flux.map ⇢ reactor.guide.FakeRepository.findAllUserByName(FakeRepository.java:27)
|_ Flux.map ⇢ reactor.guide.FakeRepository.findAllUserByName(FakeRepository.java:28)
|_ Flux.filter ⇢ reactor.guide.FakeUtils1.lambda$static$1(FakeUtils1.java:29)
|_ Flux.transform ⇢ reactor.guide.GuideDebuggingExtraTests.debuggingActivatedWithDeepTraceback(GuideDebuggingExtraTests.java:40)
|_ Flux.elapsed ⇢ reactor.guide.FakeUtils2.lambda$static$0(FakeUtils2.java:30)
|_ Flux.transform ⇢ reactor.guide.GuideDebuggingExtraTests.debuggingActivatedWithDeepTraceback(GuideDebuggingExtraTests.java:41)
테스팅
테스트 코드 작성을 위해 테스트 관련 문서를 참고해 보았습니다. io.projectreactor:reactor-test를 의존성으로 추가하고 StepVerifier를 통해 테스트 코드를 작성할 수 있었습니다. StepVerifier.create로 테스트할 객체를 만들 때 인자로 테스트 대상이 되는 Flux나 Mono를 넘깁니다. 그리고 테스트에 필요한 메서드들을 연달아서 호출해서 기대한 값이 나왔는지 확인할 수 있습니다. 여기서는 expectNext와 verifyComplete를 이용해서 next로 넘어온 값이 기대한 값인지 그리고 complete이 호출되었는지 검증해보도록 하겠습니다. 여기서 getFruitsFlux()는 지금까지 만든 예제와 관련된 Flux를 리턴하는 메서드이며, JUnit4를 이용하여 테스트해보았습니다.
@Test
public void testFruitBaskets() {
final FruitInfo expected1 = new FruitInfo(
Arrays.asList("kiwi", "orange", "lemon"),
new LinkedHashMap<String, Long>() { {
put("kiwi", 2L);
put("orange", 2L);
put("lemon", 2L);
}}
);
final FruitInfo expected2 = new FruitInfo(
Arrays.asList("banana", "lemon", "kiwi"),
new LinkedHashMap<String, Long>() { {
put("banana", 1L);
put("lemon", 2L);
put("kiwi", 1L);
}}
);
final FruitInfo expected3 = new FruitInfo(
Arrays.asList("strawberry", "orange", "lemon", "grape"),
new LinkedHashMap<String, Long>() { {
put("strawberry", 2L);
put("orange", 1L);
put("lemon", 1L);
put("grape", 1L);
}}
);
StepVerifier.create(getFruitsFlux())
.expectNext(expected1)
.expectNext(expected2)
.expectNext(expected3)
.verifyComplete();
}
테스트는 잘 통과되는 것을 확인할 수 있고, 값을 값을 하나 바꿔서 실패하게 만들면 어떤 값이 스트림에서 넘어왔는데 기대하는 값은 무엇인지도 잘 출력됩니다. 그리고 verifyComplete이 리턴하는 타입은 Duration이란 타입인데, 여기에는 테스트하는 동안 걸린 시간 정보가 들어가게 됩니다.
마치며
지금까지 간단한 예제를 이용해 Reactor의 연산자들을 어떻게 조합해서 데이터를 변환하는지, Cold에서 Hot으로 변환하는 과정을 이해하고 하나의 스트림에서 여러 스트림으로 나갈 때 어떻게 하는지, 스케줄러를 지정해 어떻게 실행 컨텍스트를 전환시켰는지 살펴보았습니다. 그밖에 log()나 디버깅 모드를 활용해서 에러난 위치나 스트림의 흐름을 쉽게 볼 수 있다는 것도 유용해 보였습니다.
스프링 프레임워크 5부터는 리액티브 프로그래밍을 할 수 있게 Reactor와 RxJava를 사용하도록 지원해주고 있지만, 현재는 실무에서 보편적으로 사용되는 것 같아 보이진 않습니다. RxJava에 익숙하다면 Reactor도 공식문서를 보고 적응하기 어렵지 않아 보였습니다.
사용하면서 어려운 점은 연산자만으로 해결이 가능한 부분이 있음에도 아직 익숙하지 않고 높은 학습곡선과 수많은 연산자들을 다 모르기에, 중간에 Flux나 Mono에서 값을 꺼내서 동기방식과 명령형 프로그래밍으로 조작한 후 다시 넣어야 하나 유혹을 받는 경우가 온다는 것입니다. 이렇게 하면 함수형 프로그래밍과 명령형 프로그래밍이 섞여 있어 코드도 복잡해지고 중간에 block 같은 연산자를 써서 논 블록킹 라이브러리의 장점을 살릴 수 없는 상황이 오게 된다는 것입니다. 따라서 Reactor를 사용하여 리액티브 프로그래밍을 해야 하는 상황을 고려한다면, 1) 필요한 이유, 2) 추후 코드 변경 시 유지보수성, 3)함께 협업하는 사람들의 숙련도나 관심 등을 고려하여 선택해야 한다고 생각합니다. 필자의 경험으로는 여러 스레드를 전환해야 해서 순서가 복잡해져서 그 사이에 순서를 잘 관리하거나, 복잡하게 데이터를 변환해야 하는 경우, 그리고 여러 스트림을 블록킹으로 처리하기보다 논 블록킹으로 처리하기 좋은 경우에 Reactor나 RxJava같은 라이브러리가 유용해 보였습니다.
이번에 Reactor를 사용해보면서 정리했으면 좋겠다는 패턴이 보여서 간단한 예제로 정리를 했습니다. 본문에서 Reactor의 모든 것을 다룰 순 없었어도, 필요한 부분이 참고가 돼서 Reactor 같은 라이브러리로 리액티브 프로그래밍을 하는데 도움이 되었으면 좋겠습니다.



